
4.1 Overview
스레드는 CPU utilization의 기본적인 단위이다.
스레드의 구성 요소로는 thread ID, PC, register set, stack 이 있으며,
code 섹션, data 섹션, 파일과 같은 프로세스 리소스는 다른 스레드들끼리 공유한다.

stack 영역은 공유하지 않음.
왜 멀티스레드를 사용할까?
예시를 들어 설명해보자.
여러 클라이언트들이 동시에 접근하는 바쁜 서버가 존재한다고 할 때,
서버 프로세스가 single-threaded 이면 한 번에 하나의 클라이언트에 대해서만 서비스가 가능하다.
그리고 나머지 클라이언트들은 대기를 해야한다.
이에 대한 해결법으로 다음과 같은 경우가 있다.
요청을 받는 프로세스가 클라이언트의 요청을 받게 되면, 요청을 처리하는 별도의 프로세스를 생성하는 방법이다.
하지만 프로세스 생성(process creation)은 시간도 오래걸리며, 자원 소모도 큰 편이다.
하지만 멀티스레드를 사용한다면, 스레드가 요청을 받게 됐을 때 새로운 스레드를 생성하여 요청을 처리하도록 하는데
이 때, 스레드 생성(thread creation)은 속도도 빠를 뿐만 아니라, 공유하는 자원이 존재하므로 자원 소모도 작다.
정리하면 멀티스레드의 장점을 다음과 같다.
- Responsiveness : 사용자에 대한 응답속도가 빠르다.
- Resource sharing
- Economy : 스레드끼리는 프로세스의 리소스를 공유한다. → creation과 context-switching이 빠르다.
- Scalability : single-threaded process는 오직 하나의 core에서만 실행 가능 (병렬 처리 불가능)
4.2 Multicore Programming
만약 single-core 환경에서 2개의 스레드를 가진 프로세스를 실행한다면 다음과 같을 것이다.
반면에, 2개의 core를 가진 환경에서 실행한다면, 다음과 같이 병렬 처리가 가능하다.
💡 Concurrency VS Parallelism
Concurrency는 1개 이상의 태스크를 수행할 수 있다는 뜻. (동시에 수행하는 것 처럼 보임?)
Parallelism은 1개 이상의 태스크를 동시에 수행할 수 있다는 뜻.
따라서, parallelism이 없는 concurrency가 가능하다.
Programming Challenges
멀티코어 시스템이 등장하면서 이를 고려하여 프로그래밍하는 것에 몇 가지 어려움이 존재한다.
- Identifying tasks : 병렬처리가 가능하도록 독립적인 태스크로 나누는 것의 어려움
- Balance : 나눠진 태스크들이 비슷한 가치를 창출하도록 하기 어려움 (ex. 특정 태스크는 전체 프로세스에 대해 별로 도움이 되지 않는 태스크일 수 있음)
- Data splitting
- Data dependency
- Testing and debugging
Types of Parallelism
병렬성에는 두 가지 타입이 존재.
- Data parallelism
- 데이터를 여러 subset으로 나누고, 각 subset에 대해 동일한 연산을 수행.
- ex) 데이터의 [0, n/2) 에 대한 sum, [n/2, n - 1] 에 대한 sum.
- Task parallelism
- 각 스레드들은 부여받은 특정한 일을 함. (unique operation)
- 각 스레드들은 동일한 데이터 또는 서로 다른 데이터를 사용.
4.3 Multithreading Models
스레드에 대한 지원은 user level과 kernel level에서 제공됨.
- User threads
- kernel보다 윗 단(user space)에서 사용.
- kernel thread에 의해 관리되지 않음.
- Kernel threads
- 운영체제에 의해 관리됨.
- 현대의 운영체제는 모두 kernel thread를 지원함.
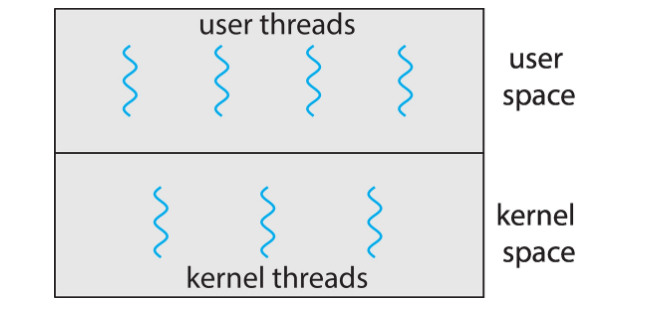
user thread와 kernel thread 간에는 관계에 따라 세 가지로 나뉜다.
Many-to-One Model
- 여러 유저 스레드가 하나의 커널 스레드에 매핑.
- 유저 스레드가 blocking 시스템 콜을 사용하면 문제 발생.
- 멀티코어 시스템인데도 멀티스레딩으로 병렬처리가 불가능.
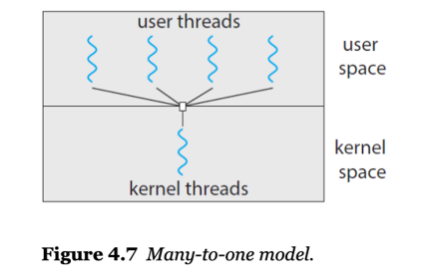
One-to-One Model
- 각 유저 스레드와 커널 스레드가 1:1로 매핑.
- 너무 많은 커널 스레드가 생성되면 과부하 발생.
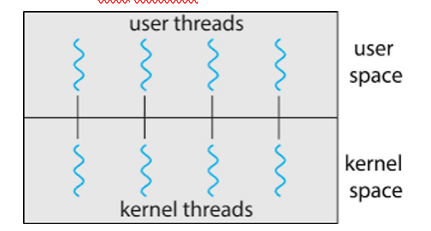
Many-to-Many Model
- 여러 유저 스레드가 보다 적거나 동일한 커널 스레드에 매핑. (user ≥ kernel)
- Many-to-One과 One-to-One의 단점들을 해결.
Thread Pools
스레드를 매번 생성, 삭제하는 방식은 시간이 많이 소모된다.
따라서 스레드를 미리 생성하여 pool에 저장해놓고, 요청이 들어오면 사용되는 Thread pools 이 사용된다.
Thread pools의 장점은 다음과 같다.
- 스레드를 매번 생성할 필요 없어 속도가 빠르다.
- 전체 스레드 개수를 제한할 수 있어 리소스의 과도한 사용을 막을 수 있다.
( 스레드풀은 os에서 관리?, 어플리케이션에서 생성하는 스레드는 user thread, 스레드풀은 모든 프로세스가 공유? 아니면 프로세스 하나당 스레드풀이 하나씩 할당?)
Threading Issues
멀티 스레스를 사용하여 프로그램을 작성할 때는 몇 가지 주의해야할 사항이 있다.
1. fork() & exec()
fork()로 복제 프로세스를 만들고 바로 exec()를 사용한다면, 부모 프로세스의 모든 스레드들을 복제할 필요가 없다.
불필요한 복제는 시간을 낭비하므로, OS가 부모 프로세스의 스레드 1개만 복제하는 fork()를 지원하는 경우 이를 고려해야 한다.
2. Signal Handling
Signal은 특정한 이벤트의 발생을 프로세스에 알리기 위해 사용된다.
이는 이벤트가 발생한 리소스나 이유에 따라 두 종류로 나뉜다.
- synchronous signal
- illegal memory access, division by 0 과 같은 작업 수행 시 발생한다.
- 시그널을 발생시킨 작업을 한 프로세스에게 전달된다.
- asynchronous signal
- 프로세스의 외부에서 발생한 이벤트에 의해 만들어 진다.
- ctrl+c, timer expire
스레드 마다 어떤 시그널을 처리하고, 어떤 시그널을 무시할 지 지정할 수 있다.
3. Thread Cancellation
스레드가 완료되기 전에 종료시키는 것으로 두 가지 시나리오가 있다.
- Asynchronous cancellation : 스레드가 다른 타겟 스레드를 즉시 종료시킨다.
- Deferred cancellation : 타겟 스레드가 종료되어야 하는지 스스로 주기적으로 체크한다.
Thread-Local Storage
각 스레드가 독립적으로 가질 수 있는 저장 공간.
로컬 변수와 혼동이 잦은데, TLS 데이터는 모든 함수들에서 접근이 가능하다는 점이 다르다.
또한 static 변수와 유사하지만, TLS 데이터는 스레드끼리 독립적으로 가진다는 점이 다르다.
'CS > OS' 카테고리의 다른 글
| [OS] CPU 스케줄링 (0) | 2024.07.16 |
|---|---|
| [OS] 프로세스 (0) | 2024.07.08 |
| [OS] 운영체제 기초 (0) | 2024.07.08 |